
Careers


More Renewables Through Better Data. kWh Analytics is making renewable energy more accessible by addressing the industry’s biggest problem: the high cost of capital.
Mission Statement
Take an in-depth look at what we do and why it matters
Company Benefits

Medical, Dental, Vision

Health Savings Account/Flexible Spending Account

401(k) Retirement Plan with Employer Matching

Commuter Benefits

Paid Time Off

Corporate Discounts

Employee Assistance Programs

All Hands

Annual Retreat

Team Events
Company Values
Entrepreneurial Mentality. Our impact exceeds our scale and resources as we venture into uncertainty to find innovative solutions to difficult problems.
Bias Towards Action. We recognize the urgency required to combat climate change and respond with immediacy and determination. We make data-driven decisions and act upon them. We find ways to scale while maintaining quality.
Always Be Learning. We have a growth mindset, embrace challenges as opportunities for growth, and encourage experimentation. We celebrate successes and learn from failures.
We Win Together. We are independent thinkers who listen to teammates, share our ideas openly, value each others’ backgrounds and perspectives, and treat each other with respect and dignity. We realize that our successes are connected.
Service Centric. We help customers succeed and strive to exceed their expectations. We demonstrate empathy and a willingness to go above and beyond to help customers achieve their goals.
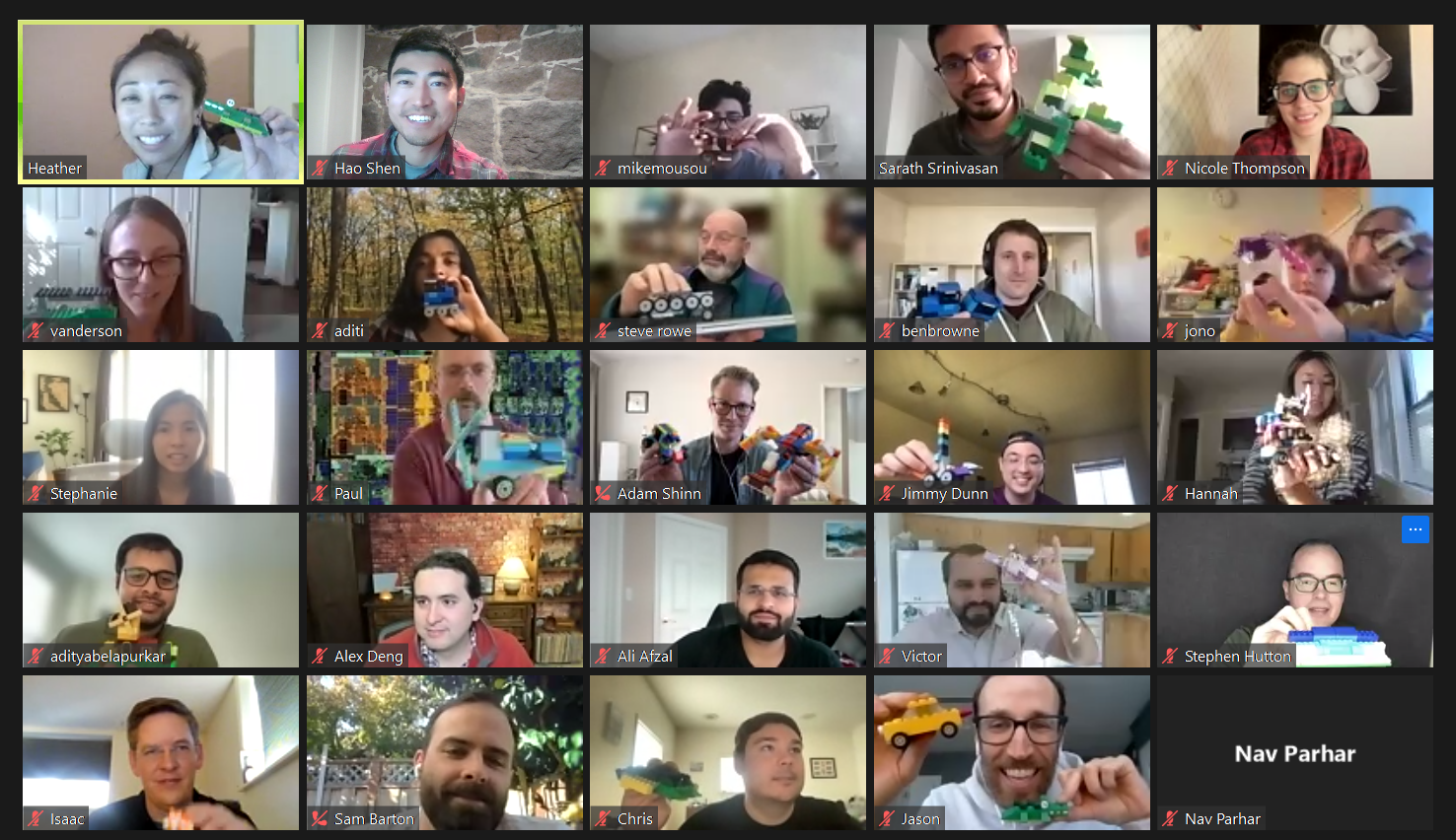





We offer the flexibility to work from home and currently have employees located across the United States, Canada, and the United Kingdom. As a remote-first company, it’s important to be intentional about building community and culture. In addition to regular virtual events, we also provide opportunities to get together in person, including our annual company retreat, team gatherings, and conferences.
Remote Work
Want your application to stand out? Learn more about our products, Heliostats and the Solar Revenue Put!
Questions, comments, or concerns? Contact people@kwhanalytics.com
kWh Analytics is an equal opportunity employer. We celebrate diversity and are committed to maintaining an inclusive environment for all employees.